Red Hat provides mainly infrastructure software like RHEL, OpenShift or OpenStack. These are established technologies for our customers but also for our partners. In order to keep the software as stable as possible, Red Hat works on doing various Quality Assurance and Continuous Integration processes. In this article we are going to focus on one specifically. The CI workflow from the point of view of a Red Hat partner.
The Red Hat’s partner use case
There are multiple kinds of partners companies, the main are what we call “hardware vendors” who are selling specific hardware, in the IT market we can see for instance companies that sell servers, networking components, hardware storage solutions, etc… There is also the Independent Software Vendor (ISV) who are selling specific software solutions in various areas.
The common denominator between all these companies is that when it comes to integrating their stack with the Red Hat ones to provide a complete solution for their customers: they do want to minimize as much as possible the number of bugs. Also, the ice of the cake would be to start this integration as early as possible, ideally it should begin before the products (on both sides) are released (General Availability - GA). This is typically the use case when the Red Hat DCI workflow comes into place.
The DCI workflow
The main idea behind DCI is to integrate and test together multiple (un)-released software in order to be predictive (which software combos are working correctly ?) and provide useful insights for both, Red Hat andthe partners. To do so, Red Hat engineers and the partners engineers are collaborating together for the full integration, once this is done the DCI automation might replay the process as new unreleased software is pushed.
Another very important benefit of such workflow is that all these tests take place inside partners walls with their own specific hardware and configuration. This allows Red Hat to reduce part of the CI cost and to leverage partner’s knowledge for their stack (partners know the best of their own software!) thus avoiding some consulting or learning curve.
Let’s explore how all these concepts are articulated !
The DCI concepts
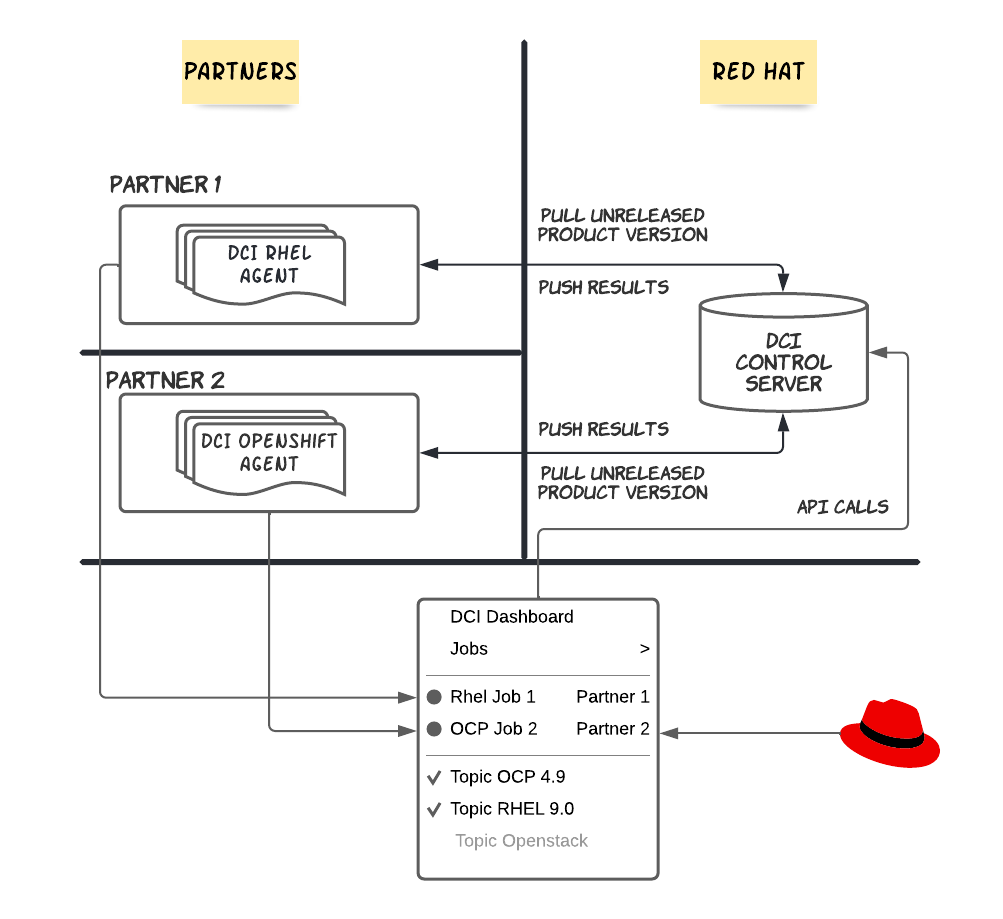
The Control Server and its dashboard
As you saw above, we decided to centralize all the partner’s interactions in a unique place called the Control Server. It’s a multi-tenant RESTful API that provides the necessary resources to run the CI jobs. The dashboard is the main user interface for the partners to visualize their jobs results. Lets see what it looks like:
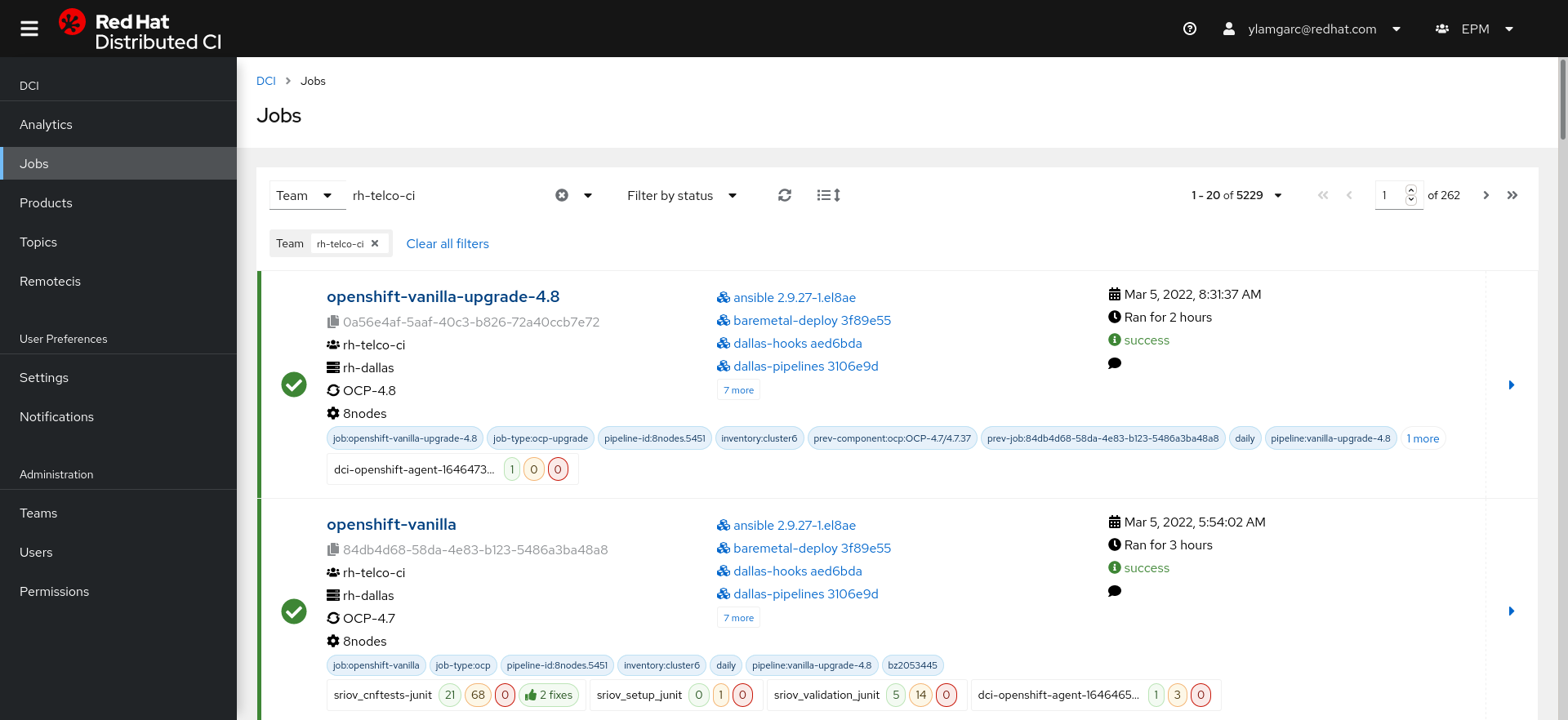
When partners are on-boarded, they are firstly invited to sign in with their Red Hat account through the dashboard, the first login will automatically create a partner account into the DCI database. At this point an administrator may add the partner’s account into a team. The notion of a team is very important because this is how we isolate one partner from another (a partner must not see the activities of another one), we usually create one team per partner.
What is the difference between an agent and a remote ci ?
Once the partner is attached to his team, the first thing he wants to do is to run a job of course ! But before doing so, they must create what we call a “remote ci”. A remote ci is how we identify a partner platform. In fact, when a job is created in the control server, the remote ci should clearly identify where it has been run, it's an important piece of information because a partner might have multiple platforms with different hardware configurations.
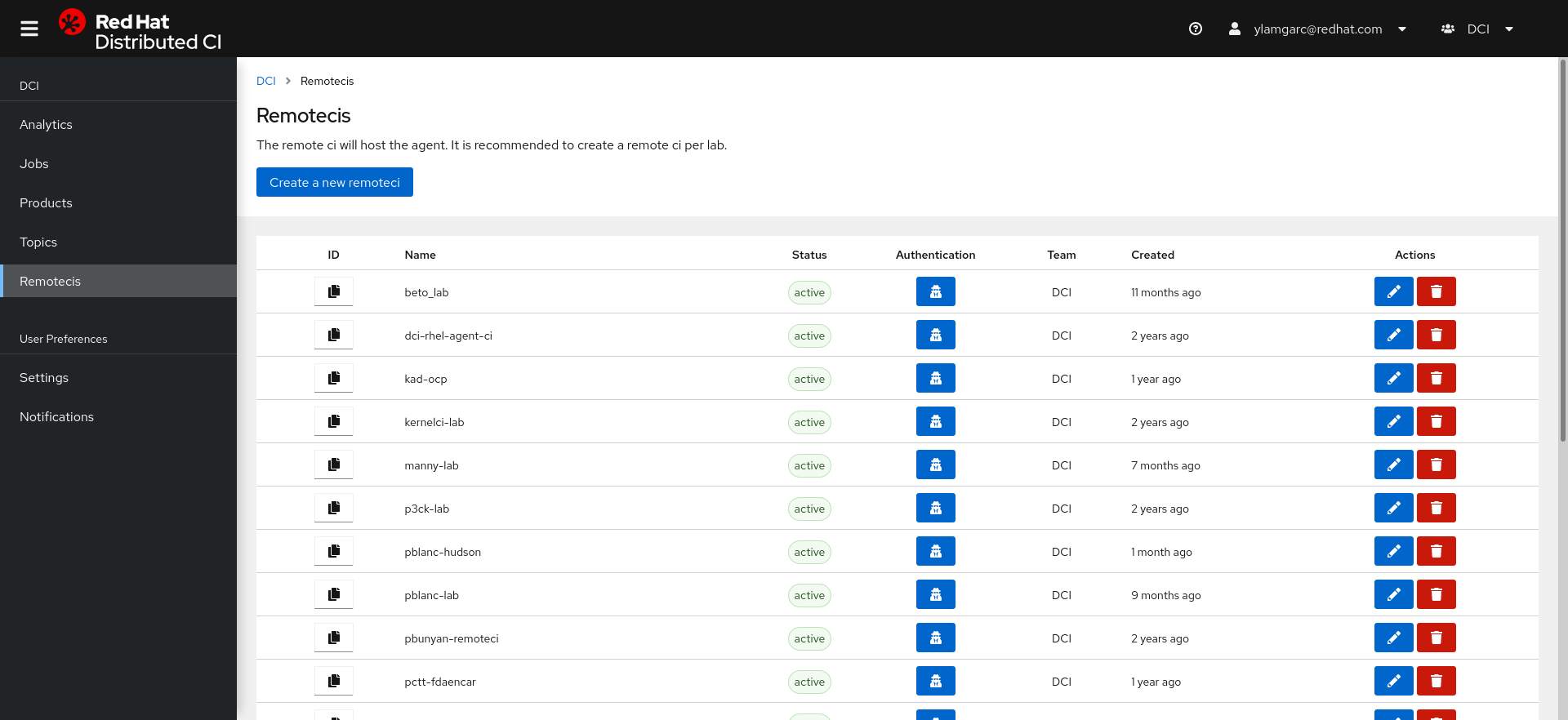
In practice, a remote ci is acting like a “user” with it’s own authentication mechanism and it’s credentials are used by the agent to interact with the control server’s api. So what is a DCI agent ?
An agent is in charge of effectively running the job at the partner’s platform and reporting back to the control server. Today we are offering one agent per product, we support Openshift, RHEL and Openstack.
All agents are Ansible based and they drive their respective Red Hat’s installer to deploy the product in the partner’s platform. The plumbing to the Control Server is done transparently thanks to a specific Ansible callback plugin. A mechanism based on “hooks” gives the opportunity to the partner to plug in their specific tasks during the run of a job, this way it’s possible to easily customize the deployment for their specific needs.
What is a job and why are components so important ?
A job is the representation of the output of an agent through a given remote ci. It’s represented as below:
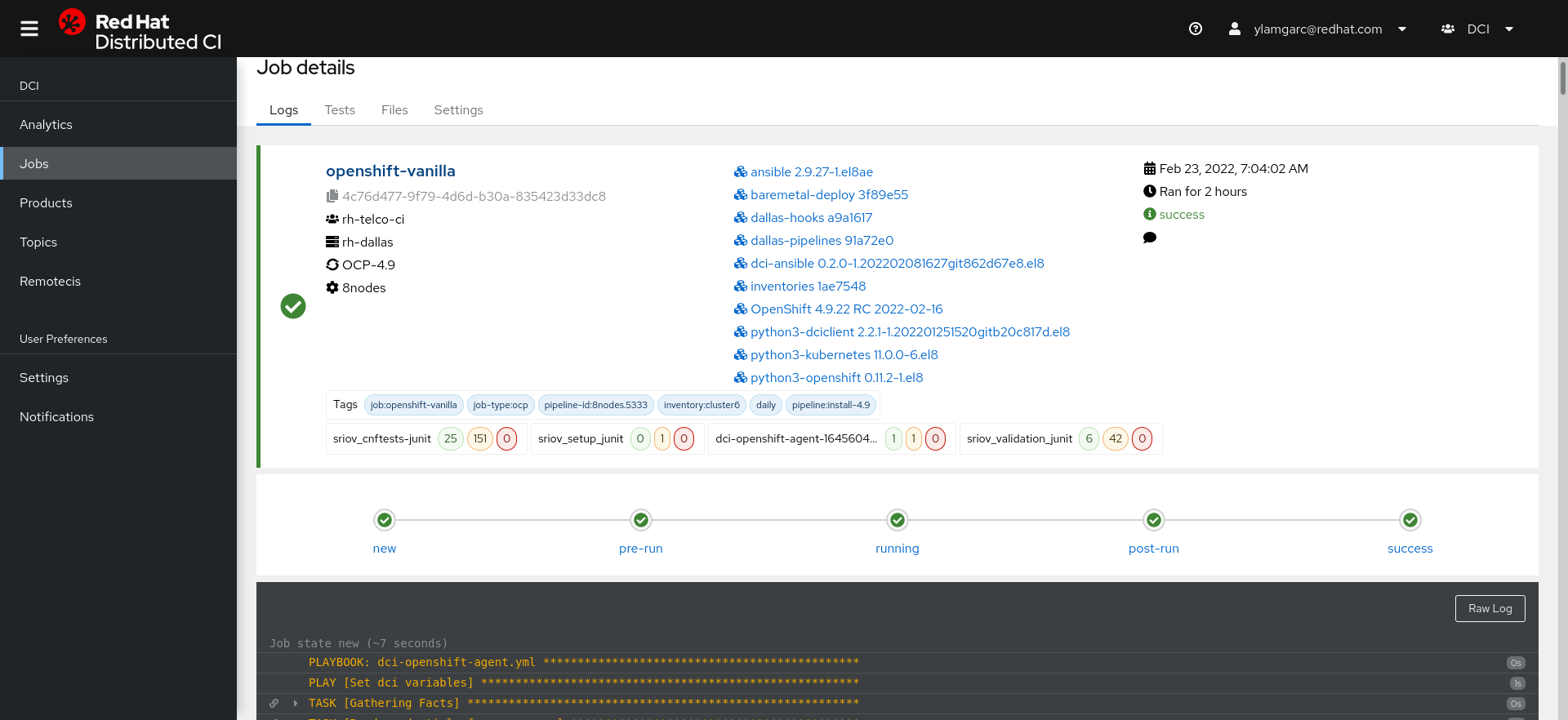
It is at the center of all DCI concepts and is composed of several artifacts that we are going to describe. When a job is running we can split it’s progression into several steps, each step is called a Jobstate. Usually a job does the following:
- new: schedule a job
- pre-run: prepare the environment
- pre-run: download the required artifacts
- running: deploy the product
- running: run some tests
- post-run: finally upload some logs and tests results
- success, failure, error: final status
The benefits of having such a taxonomy is that it eases the post-mortem analysis and allows to have various measurements of each step to detect anomalies. Also, analytics tools might be plugable on top of this mechanism.
A job always runs against something that we are interested in, for example in RHEL it could be an unreleased Compose, for Openshift it could be a nightly version, etc… All these kinds of artifacts are called Components. More specifically the Components represent everything that is related to the context of execution of a job and help to understand the job’s results.

In a CI world, the sinews of the war is the repeatability ! Indeed, when a job is failing we do want to understand why and more importantly we do want to be able to reproduce this failure. To do so, the job can specify as many components as required, usually the agents can explicitly list dependencies to be added as components in the job. In our Ansible based agents we enforced this practice with a special Action plugin to automatically create components when some repos are cloned.
Finally, the latest reported artifact is what we call a File, it could be a Rhel sos-report, an Openshift must-gathers tarball, service logs, etc… You got it, everything that might be useful for troubleshooting !
How to choose a specific version stream with a topic ?
In the previous section we saw the way components are related to the jobs but how components are sorted out ? How to run a job with a specific version of a product ? This is the goal of the DCI Topics.
A product is usually released under a specific version, this version is following a schema, the most commonly used is semver that follow the nomenclature “MAJOR.MINOR.PATCH”, for example Openshift 4.9.1.
In DCI, we provide a stream for each “MAJOR.MINOR”, for example OpenShift 4.9, Rhel 8.4, etc.... These streams are called topics, a team can subscribe to some topics of interest depending on their needs.
When the agent asks the Control Server to schedule a job, it must provide the topic on which to instantiate the job. By default the server will get the latest version available for this topic, for example in the topic OpenShift 4.9 it would be OpenShift 4.9.23. For various reasons some partners might want to pin a component, for instance to reproduce a bug. In this case the agent adds the component identifier along with the topic. This is easily configurable in the agent’s settings.
Conclusion
In this article we went over the Distributed CI concepts to understand how Red Hat is able to extend their CI outside of their walls up to the partner’s platforms. With DCI Red Hat might integrate the partner's stack with un-released Red Hat products thus improving the global testing coverage and be prepared as much as possible for the General Availability.
In this area we can go even further ! Indeed, DCI promotes and eases best CI practices for the partners like continuous certification. This will allow the partners to be sure they are constantly Red Hat Certified and ready for the General Availability thus reducing partner’s time to market.
To test complex scenarios, DCI also provides a complete pipeline tooling for orchestrating such jobs ! All these nice features will be covered in other articles so stay tuned ;) !
